javascript
vue.js
el
内核开发
JUC
webpack
双目相机
armv9
pdf
美食分享系统
共阴极-共阳极判定
mount
plugin
symbol
盒子模型
Conditional注解
AI求解器
DDD领域驱动设计
parser
TF-A
模型微调
2024/4/26 3:15:01
【AI视野·今日NLP 自然语言处理论文速览 第六十四期】Fri, 27 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Fri, 27 Oct 2023 Totally 80 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
torchdistill Meets Hugging Face Libraries for Reproducible, Coding-Free Deep Learning Studies: A Case …

peft模型微调--Prompt Tuning
模型微调(Model Fine-Tuning)是指在预训练模型的基础上,针对特定任务进行进一步的训练以优化模型性能的过程。预训练模型通常是在大规模数据集上通过无监督或自监督学习方法预先训练好的,具有捕捉语言或数据特征的强大能力。
PEF…
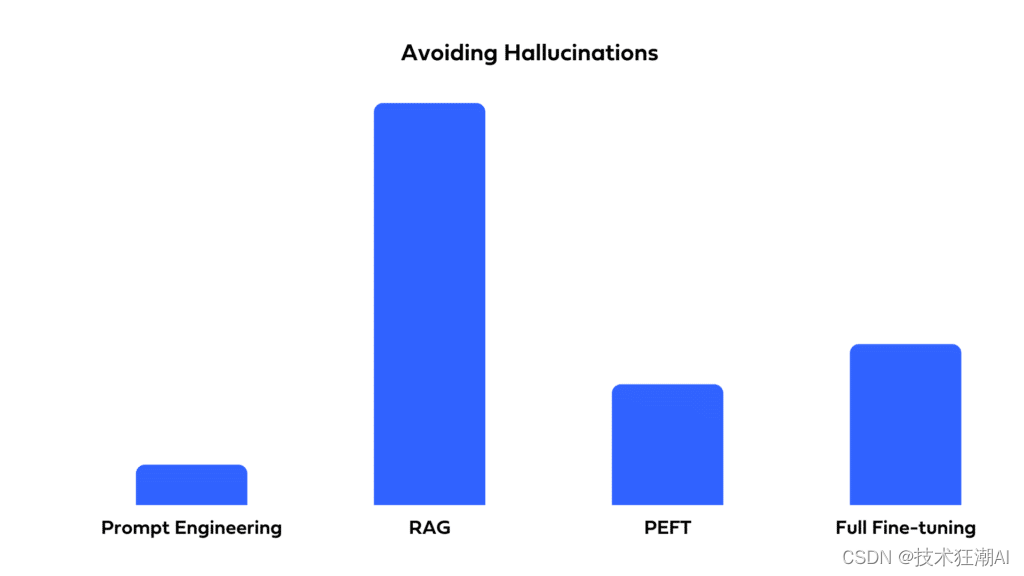
如何选择最适合你的LLM优化方法:全面微调、PEFT、提示工程和RAG对比分析
一、前言
自从ChatGPT问世以来,全球各地的企业都迫切希望利用大型语言模型(LLMs)来提升他们的产品和运营。虽然LLMs具有巨大的潜力,但存在一个问题:即使是最强大的预训练LLM也可能无法直接满足你的特定需求。其原因如…
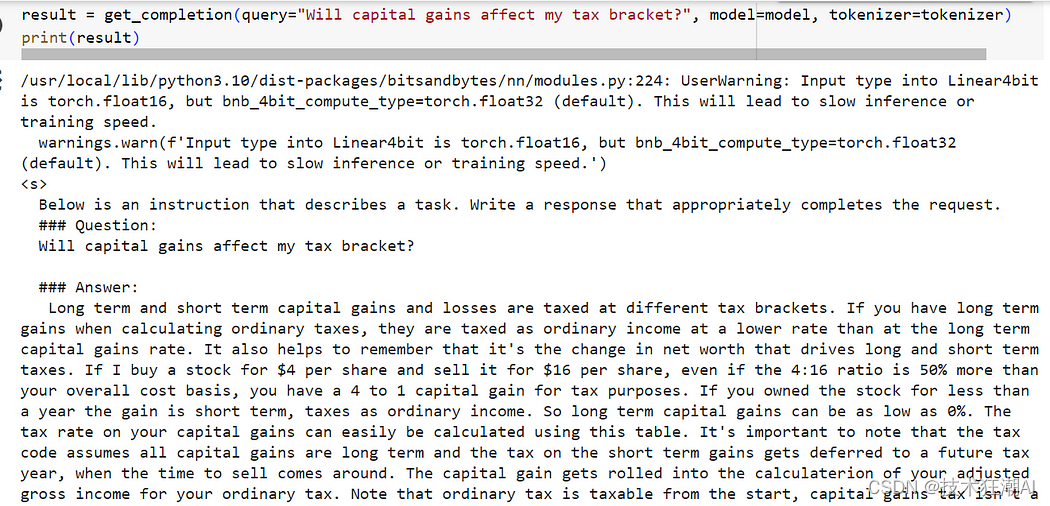
如何使用LoRA和PEFT微调 Mistral 7B 模型
一、前言
对于大模型在一些安全级别较高的领域,比如在金融服务领域实施人工智能解决方案时,面临的最大挑战之一是数据隐私、安全性和监管合规性。
因为担心数据泄露的问题,很多银行或机构都会回避利用人工智能的优势潜力,尤其是…
GPT-LLM-Trainer:如何使用自己的数据轻松快速地微调和训练LLM
一、前言
想要轻松快速地使用您自己的数据微调和培训大型语言模型(LLM)?我们知道训练大型语言模型具有挑战性并需要耗费大量计算资源,包括收集和优化数据集、确定合适的模型及编写训练代码等。今天我们将介绍一种实验性新方法&am…

大模型增量预训练新技巧:解决灾难性遗忘
大家好,目前不少开源模型在通用领域具有不错的效果,但由于缺乏领域数据,往往在一些垂直领域中表现不理想,这时就需要增量预训练和微调等方法来提高模型的领域能力。
但在领域数据增量预训练或微调时,很容易出现灾难性…
【通义千问】大模型Qwen GitHub开源工程学习笔记(5)-- 模型的微调【全参数微调】【LoRA方法】【Q-LoRA方法】
摘要: 训练数据的准备
你需要将所有样本放到一个列表中并存入json文件中。每个样本对应一个字典,包含id和conversation,其中后者为一个列表。示例如下所示:
[{"id": "identity_0","conversations": [{"from": "user",…
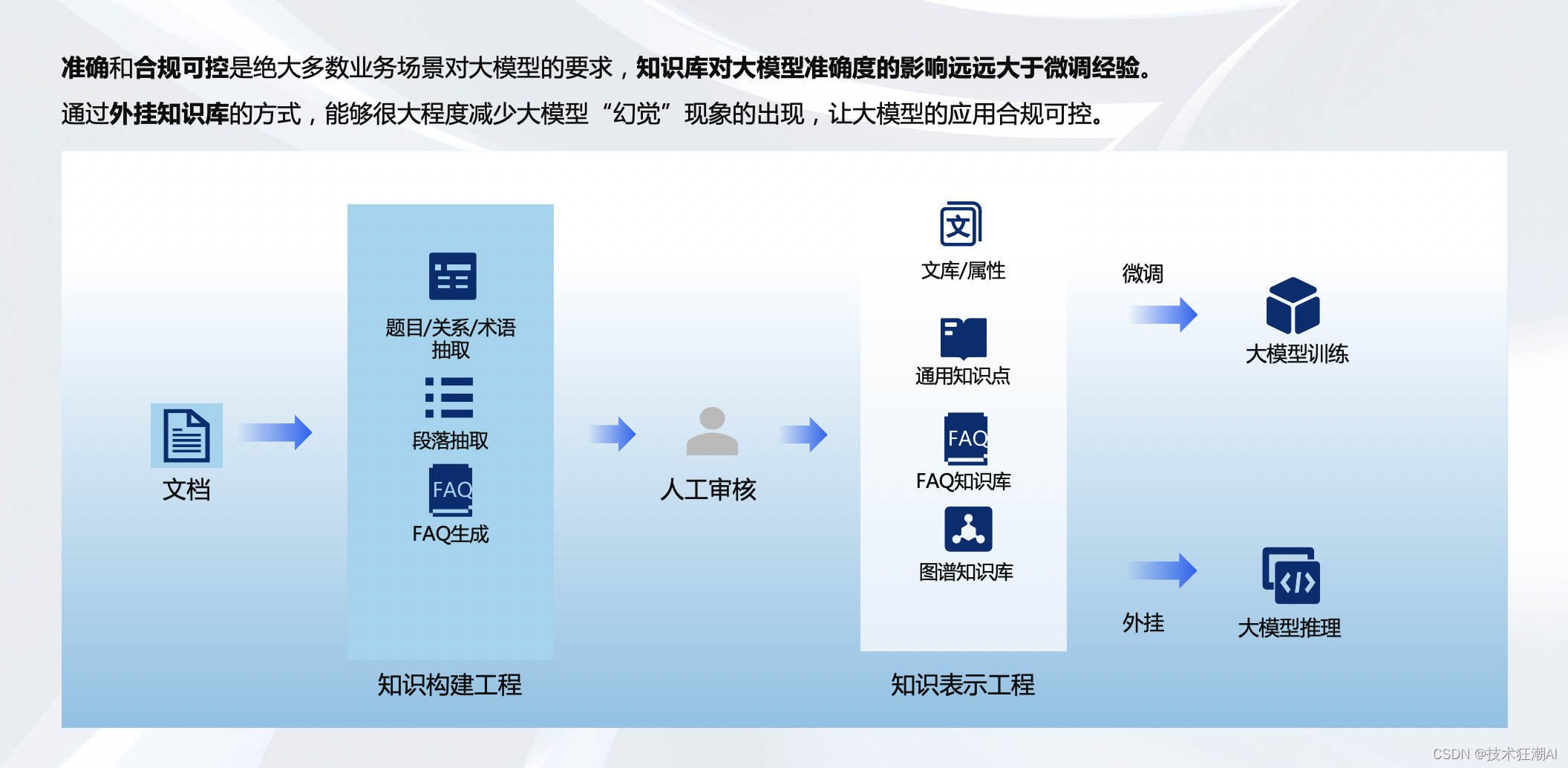
大模型在企业知识库场景的落地思考
一、引言
在这个信息爆炸的时代,企业的知识库已不再是简单的数据堆砌,而是需要智能化、高效率的知识管理和利用。大模型作为AI领域的一个重要突破,正逐步成为企业知识库管理的强大助力。通过前面一段时间对于大模型在企业落地的深入调研和实…

用通俗易懂的方式讲解:大模型微调方法总结
大家好,今天给大家分享大模型微调方法:LoRA,Adapter,Prefix-tuning,P-tuning,Prompt-tuning。
文末有大模型一系列文章及技术交流方式,传统美德不要忘了,喜欢本文记得收藏、关注、点赞。 文章目录 1、LoRA…
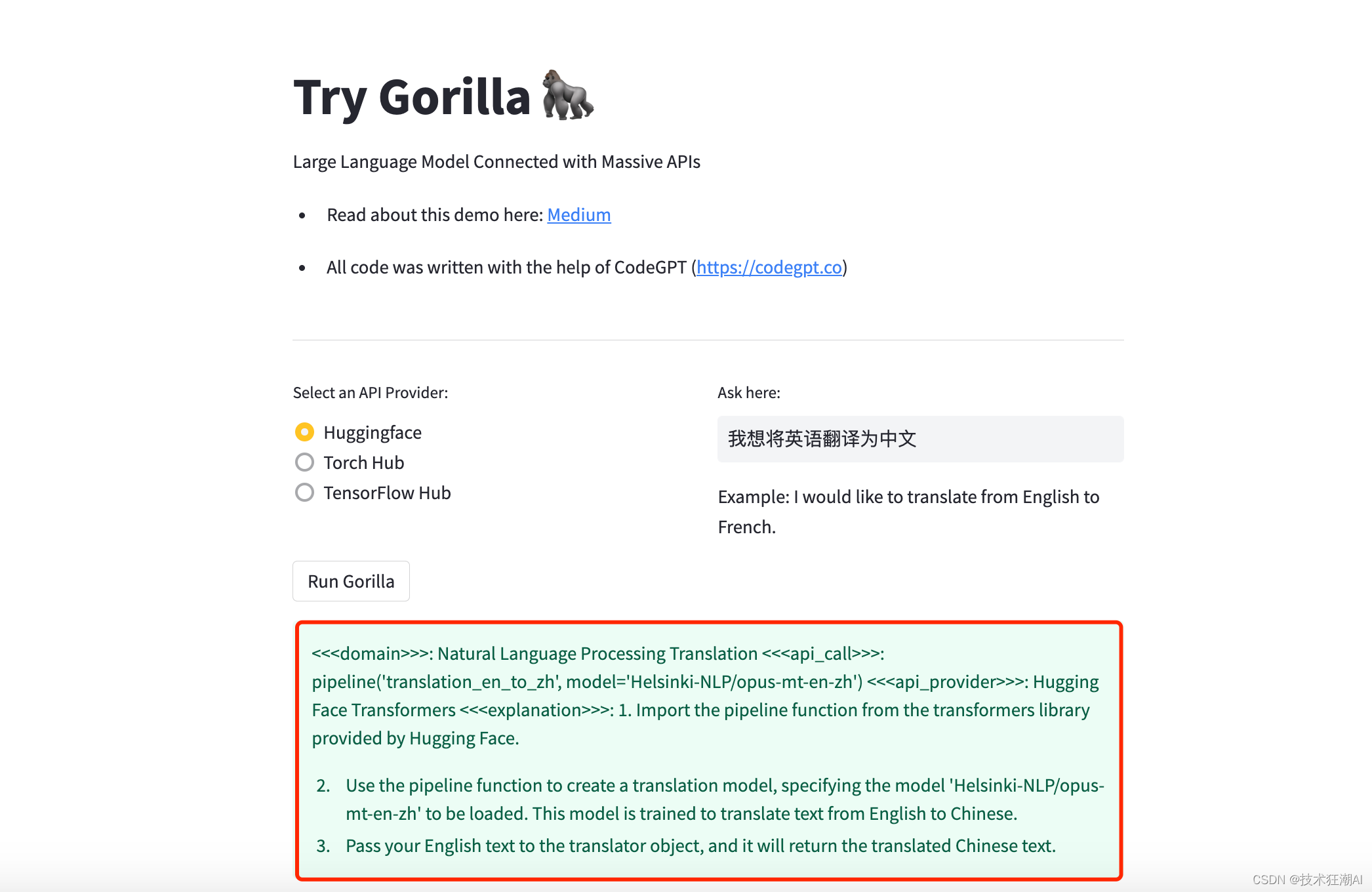
Gorilla LLM:连接海量 API 的大型语言模型
如果你对这篇文章感兴趣,而且你想要了解更多关于AI领域的实战技巧,可以关注「技术狂潮AI」公众号。在这里,你可以看到最新最热的AIGC领域的干货文章和案例实战教程。 一、前言
在当今这个数字化时代,大型语言模型(LLM…
Llama2-Chinese项目:1-项目介绍和模型推理
Atom-7B与Llama2间的关系:Atom-7B是基于Llama2进行中文预训练的开源大模型。为什么叫原子呢?因为原子生万物,Llama中文社区希望原子大模型未来可以成为构建AI世界的基础单位。目前社区发布了6个模型,如下所示:
FlagAl…

【LLM模型篇】LLaMA2 | Vicuna | EcomGPT等(更新中)
文章目录 一、Base modelchatglm2模型Vicuna模型LLaMA2模型1. 训练细节2. Evaluation Results3. 更多参考 alpaca模型其他大模型和peft高效参数微调二、垂直领域大模型MedicalGPT:医疗大模型TransGPT:交通大模型EcomGPT:电商领域大模型1. s…